PySpark で利用可能な分散メモリ データセット (非永続ストレージ) としては、従来の RDD (Resilient Distributed Datasets) の他に、Spark から提供される (pandas.DataFrame ではない) DataFrames があります。DataFrames は、RDD より高速で、かつ、テーブル型で SQL ライクなメソッドを持つなど、高機能であり、今後は、DataFrames が主流になって行きます。
Spark では、Machine Learning ライブラリとして、spark.mllib と spark.ml の2つがありますが、前者が RDD、後者が DataFrames に対応しています。RDD と DataFrames の関係同様、今後は、spark.ml が主流になって行く予定です。
DataFrames は、名前付きのテーブル型分散メモリ データセットになりますので、名前がない状態でデータ処理を行うシーン、例えば、ヘッダー無しの CSV データなどをそのまま読み込んで処理する場合は、RDD を使う方が便利な場合もあります。
RDD を使ってみる
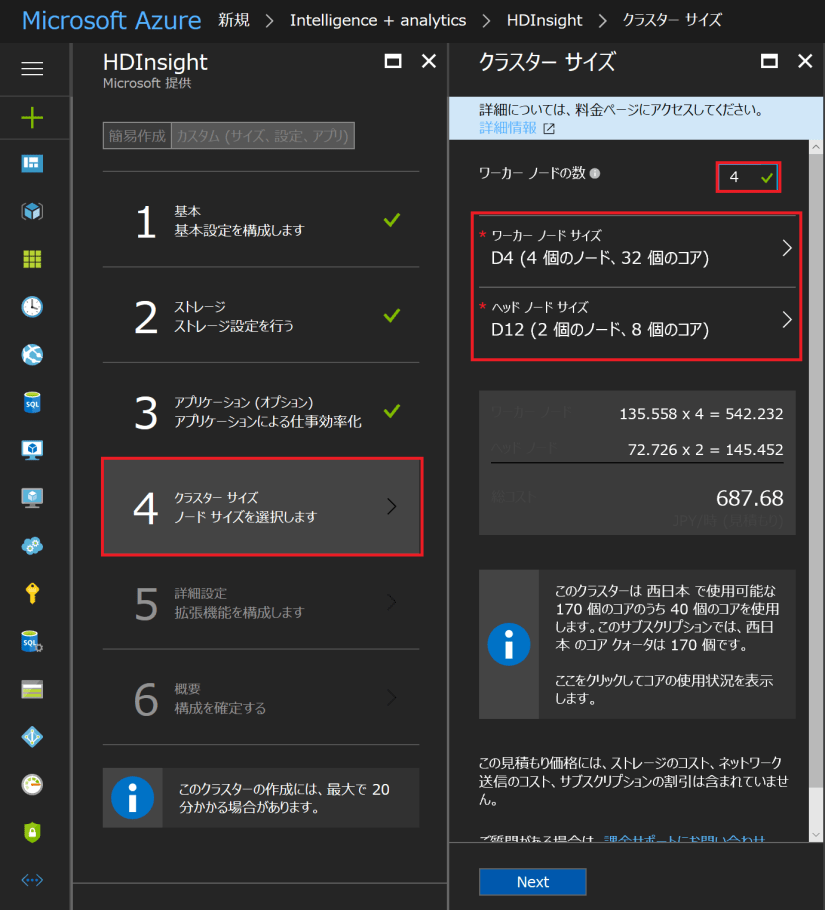
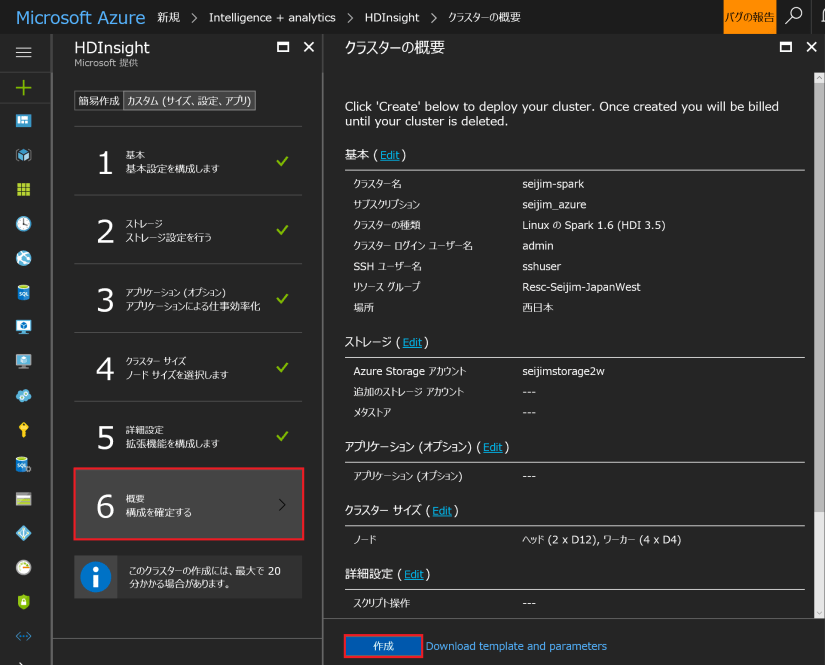
Azure ポータルにログインして、Spark を作成した「リソースグループ」、もしくは、「HDInsight」から辿って、自分で作成した Spark クラスター名 (ここでは、seijim-spark) を選択します。「Overview」⇒「クラスター ダッシュボード」 ⇒「Jupyter Notebook」を起動します。「New」⇒「PySpark3」で、Notebook ファイルを新規で立ち上げます。
Spark クラスターをディプロイした BLOB Storage にはサンプルデータが配置されていますので、その CSV データを利用してみます。Notebook ファイルに名前を付けた後、以下のようにセルにコードを入力しながら、セル単位に実行してみてください。
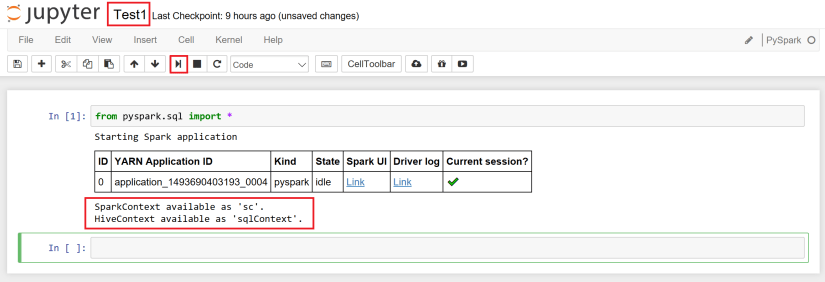
from pyspark.sql import *
# Use Hive Context
sqlContext = HiveContext(sc)
# Create an RDD from sample data
rdd_data = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")
# Show top 10 of rows
rdd_data.take(10)
# Create a schema for our data
hvacHeader = Row('Date', 'Time', 'TargetTemp', 'ActualTemp', 'BuildingID')
# Parse the data and create a schema
hvacData = rdd_data.map(lambda s: s.split(',')).filter(lambda s: s[0] != 'Date')
hvac = hvacData.map(lambda p: hvacHeader(str(p[0]), str(p[1]), int(p[2]), int(p[3]), int(p[6])))
hvac.first()
実行した結果は、以下のようになります。

2番目のセルで、CSV から RDD を生成しています。
3番目のセルは、上位 10 行を取得しています。
4番目のセルでは、ヘッダーとデータ部をマップして、名前付きの RDD を生成しています。
5番目のセルでは、先頭行を取得しています。
DataFrames を使ってみる
DataFrames は、テーブル型の分散メモリ データセットです。つまり、SQL (Like な) 操作と非常に相性が良いということになります。
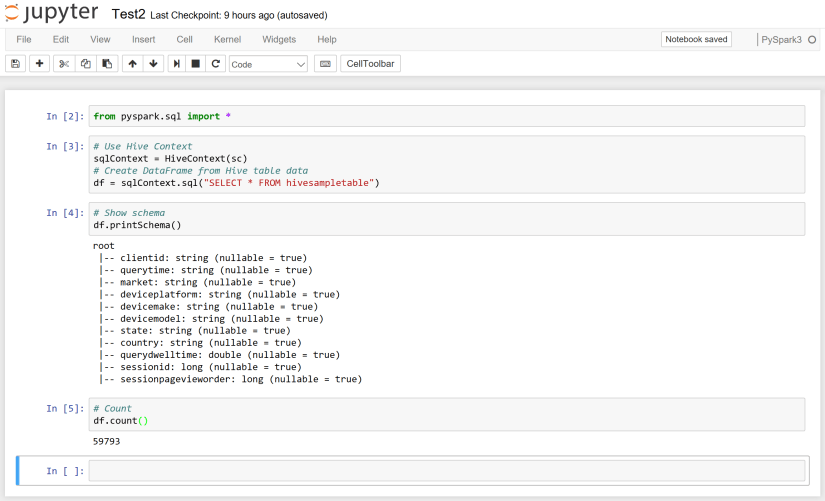
今度は、Hive のサンプルテーブルから DataFrame を生成します。新しい Notebook を起動して、以下のようにセルに入力し、セル単位に実行してみてください。
from pyspark.sql import *
# Use Hive Context
sqlContext = HiveContext(sc)
# Create DataFrame from Hive table data
df = sqlContext.sql("SELECT * FROM hivesampletable")
# Show schema
df.printSchema()
# Count
df.count()
実行した結果は、以下のようになります。
続いて、以下のようにセルに入力しながら、セル単位に実行します。
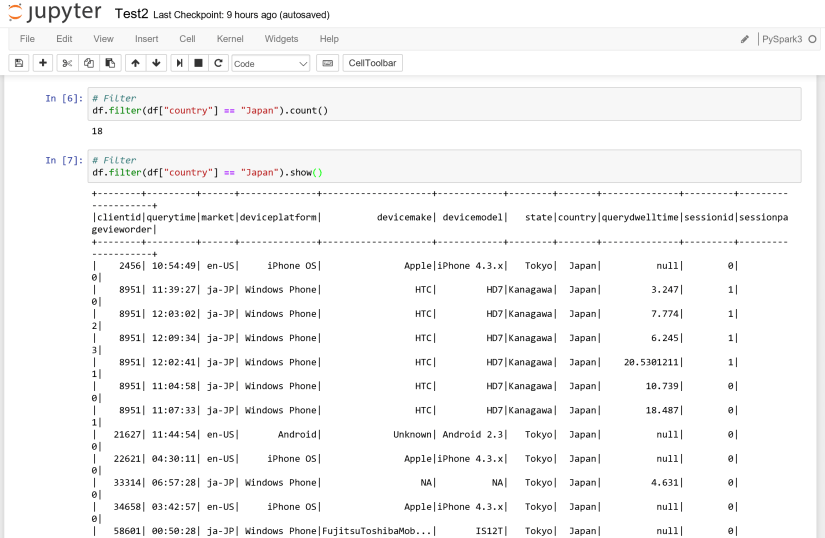
# Filter
df.filter(df["country"] == "Japan").count()
# Filter
df.filter(df["country"] == "Japan").show()
実行した結果は以下のようになります。
続いて、以下のようにセルに入力し、セル単位に実行します。
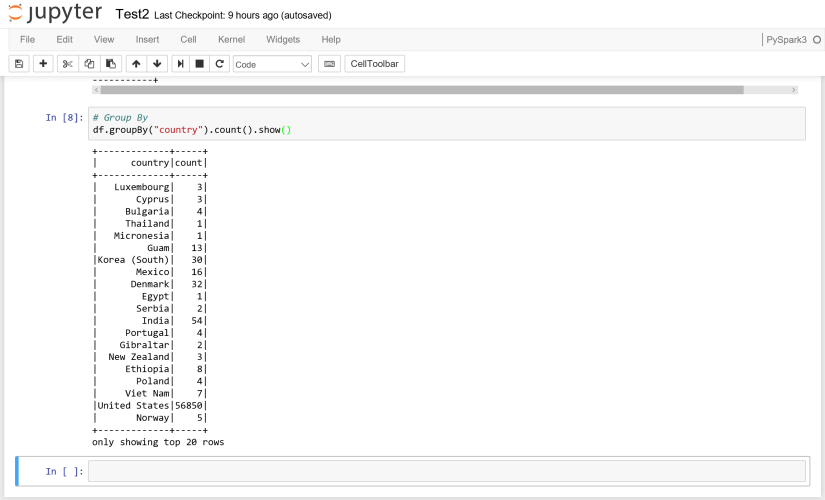
# Group By
df.groupBy("country").count().show()
実行した結果は、以下のようになります。
RDD と DataFrames の基本的な使い方をご紹介しましたが、API の詳細は以下の「参考」をご覧ください。
Next ⇒ Spark on HDInsight を使ってみる (5) – JDBC を利用した SQL Database / SQL Data Warehouse へのアクセス
[参考]
Spark Programming Guide (v2.1)
Spark SQL, DataFrames and Datasets Guide (v2.1)
日本語での RDD API 説明 (Scala 用ですが、PySpark でも同様です)