Spark 1.6 (HDInsight 3.5) では、″/usr/hdp/2.5.4.0-121/hive/lib″ ディレクトリ以下に、SQL Server 用の JDBC Driver (sqljdbc41.jar) がインストール済みの為、IaaS の SQL Server、Azure SQL Database、Azure SQL Data Warehouse に対して、JDBC 接続文字列だけですぐにアクセスが可能です。
Azure SQL Database からの読み取り
事前に、SQL Server Management Studio などを利用して、Azure SQL Database に以下のテーブルとデータを作成しておいてください。SQL Server や SQL Database に馴染みのない方は、リテラル値の前の「N」が気になるかと思いますが、これは UNICODE のリテラル値であることを表します。
CREATE TABLE [test].[T1](
[mykey] [nvarchar](100) PRIMARY KEY CLUSTERED NOT NULL,
[myvalue] [nvarchar](1000) NULL
) WITH (DATA_COMPRESSION=PAGE)
GO
INSERT INTO [test].[T1] (mykey,myvalue) VALUES (N'1',N'パイナップル'),(N'2',N'アップル'),(N'3',N'ペン')
GO
次に、Azure ポータルにログインして、Spark を作成した「リソースグループ」、もしくは、「HDInsight」から辿って、自分で作成した Spark クラスター名 (ここでは、seijim-spark) を選択します。「Overview」⇒「クラスター ダッシュボード」 ⇒「Jupyter Notebook」を起動します。「New」⇒「PySpark3」で、Notebook ファイルを新規で立ち上げます。Notebook ファイルに名前を付けた後、以下のようにセルにコードを入力しながら、セル単位に実行してみてください。
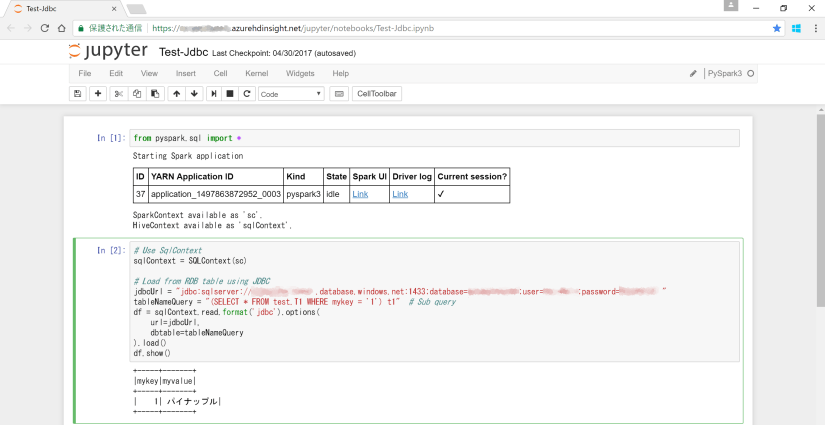
from pyspark.sql import *
# Use SqlContext
sqlContext = SQLContext(sc)
# Load from RDB table using JDBC
jdbcUrl = "jdbc:sqlserver://********.database.windows.net:1433;database=********;user=********;password=********"
tableNameQuery = "(SELECT * FROM test.T1 WHERE mykey = '1') t1" # Sub query
df = sqlContext.read.format('jdbc').options(
url=jdbcUrl,
dbtable=tableNameQuery
).load()
df.show()
実行した結果は以下のようになります。
Azure SQL Database への書き出し (INSERT)
Notebook 上で、新しい DataFlame を作成し、それを追記型で Azure SQL Database に書き出し (INSERT) を行います。以下のようにセルにコードを入力しながら、セル単位に実行してみてください。
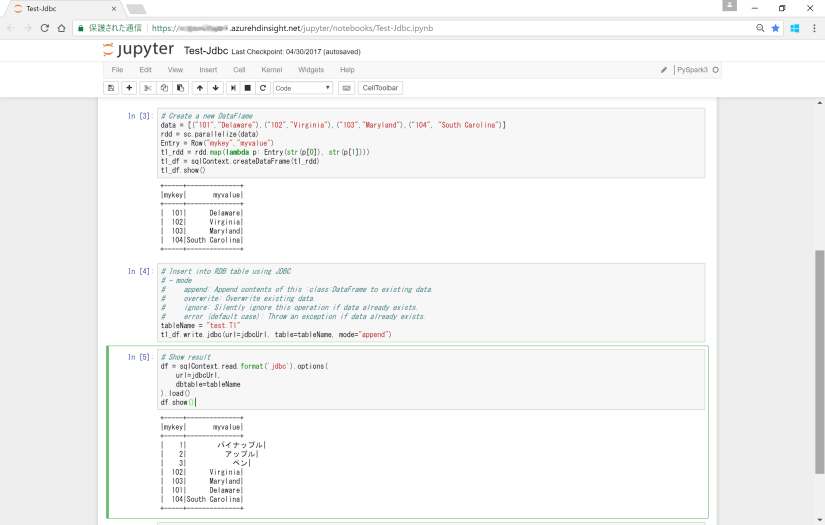
# Create a new DataFlame
data = [("101","Delaware"),("102","Virginia"),("103","Maryland"),("104", "South Carolina")]
rdd = sc.parallelize(data)
Entry = Row("mykey","myvalue")
t1_rdd = rdd.map(lambda p: Entry(str(p[0]), str(p[1])))
t1_df = sqlContext.createDataFrame(t1_rdd)
t1_df.show()
# Insert into RDB table using JDBC
# - mode
# append: Append contents of this :class:DataFrame to existing data.
# overwrite: Overwrite existing data.
# ignore: Silently ignore this operation if data already exists.
# error (default case): Throw an exception if data already exists.
tableName = "test.T1"
t1_df.write.jdbc(url=jdbcUrl, table=tableName, mode="append")
# Show result
df = sqlContext.read.format('jdbc').options(
url=jdbcUrl,
dbtable=tableName
).load()
df.show()
結果は以下のようになります。
書き出しのモード (mode) に、”overwrite” を指定すると、既存のテーブルが DROP されるので、注意が必要です。
Next ⇒ Spark on HDInsight を使ってみる (6) – Hive を活用する
[参考]
