前回 (2) は、ローカル開発していた Jupyter Notebook の資産移行の説明もしましたので、じゃ、ローカルで開発したら良いじゃんとなるかもしれませんが、やはり Spark 上の Python (PySpark) では、並列環境特有のお作法がありますので、先ずは、Spark on HDInsight から提供されている Jupyter Notebook を使ってみましょう。
Jupyter Notebook の起動
Azure ポータルにログインして、Spark を作成した「リソースグループ」、もしくは、「HDInsight」から辿って、自分で作成した Spark クラスター名 (ここでは、seijim-spark) を選択します。「Overview」⇒「クラスター ダッシュボード」 をクリックします。

クラスター ダッシュボードから Jupyter Notebook を起動します。
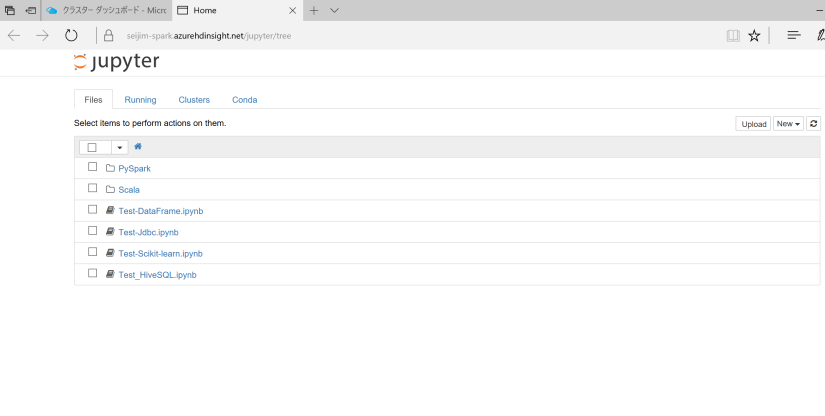
新規で作成された方は、PySpark フォルダーと Scala フォルダーのみがある状態ですが、前回 (2) のように BLOB Storage を使って、Notebook ファイルを移行された方は、以下のように Notebook ファイルが見えるはずです。
ここから新規の Notebook ファイルを作成してみます。「New」をクリックして、「PySpark」(Python 2.7 系) 、もしくは、「PySpark3」(Python 3.x 系) のどちらかを選択します。ここでは、「PySpark3」を選択します。

タイトルを編集 (ここでは Test1) し、以下のように pyspark.sql パッケージのインポート コマンドだけを最初のセルに入力して、セルの実行ボタンをクリックしてみます。
from pyspark.sql import *
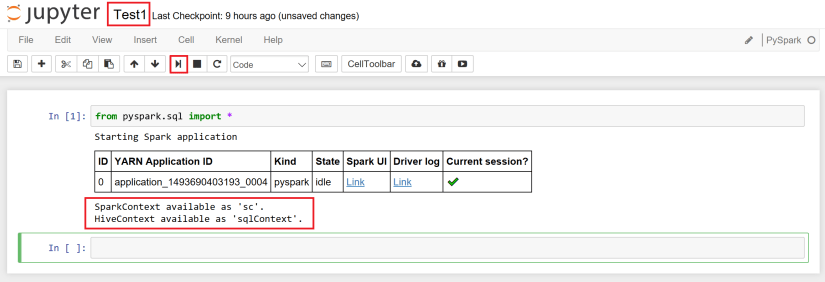
実行が完了すると、上記のように YARN Application ID などのジョブ実行情報が表示され、SparkContext は “sc” として、HiveContext は “sqlContext” として利用できる旨が表示されます。ここが、ローカル環境とは大きく違うところで、HDInsight (Hadoop) が後ろにいるなぁというところを実感できる部分でもあります。
Hive は、Map-Reduce を SQL 言語で操作できる分散型データプラットフォームで、sqlContext を利用して、すぐに利用することが可能です。
Notebook ファイルの終了方法
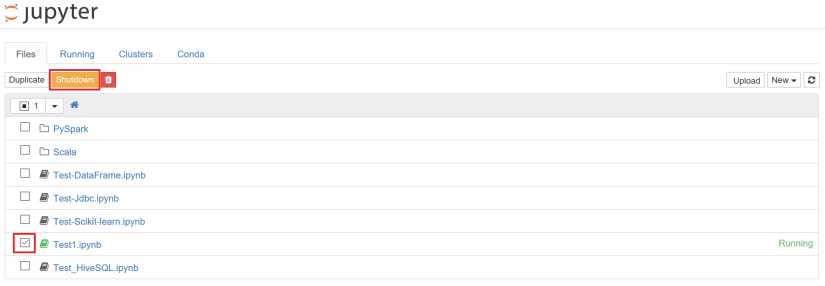
先程開いていた Notebook ファイル「Test1」をブラウザで終了 (タブを閉じるなど) してみます。Jupyter Notebook のホームを見ると、「Test1.ipynb」のステイタスが「Running」であるのが分かります。これは、Spark 上のセッションが維持され、メモリリソースなどが確保されたままの状態なのです。
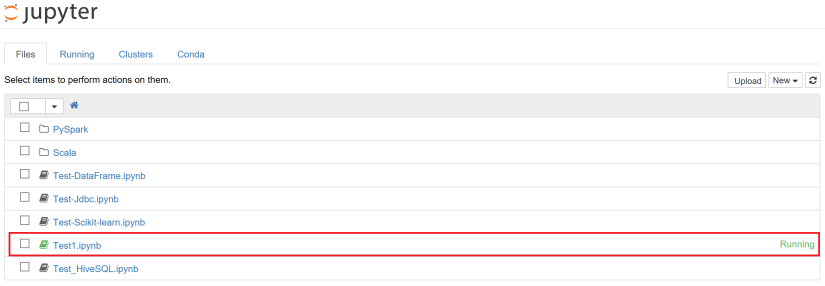
これでは、共有環境となる Spark では他への影響が出る為、利用が終了していて、誤ってブラウザで終了していたとしたら、以下のように対象の Notebook ファイルを選択して、 Shutdown ボタンをクリックしてください。
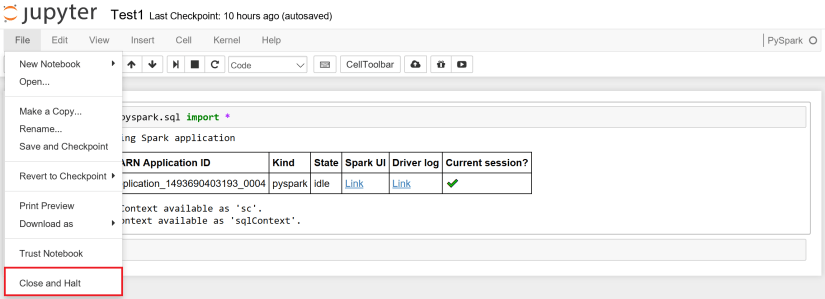
本来の Notebook ファイルの終了方法は、以下のように「File」メニューから「Close and Halt」を選択してください。これで、セッションが開放されます。
Next ⇒ Spark on HDInsight を使ってみる (4) – 分散メモリ データセット RDD & DataFrames
