Spark クラスターが出来上がったので、早速、使ってみたいと思います。Spark は、Spark SQL というデータ分析用途として利用することも出来ますし、MLLIB や ML などの機械学習 (Machine Learning) 用の並列処理ライブラリも整備されていますので、機械学習プラットフォームとしても利用できます。
さて、Spark と言っても、HDInsight という PaaS 上に存在していますので、はて、どうやって、Python のパッケージをインストールしたり、どこに自製したライブラリーファイルを置けば良いのだろうという部分が気になります。そういう前提知識から先ずはご紹介します。
外部パッケージのインストール方法
スクリプト アクション (スクリプト操作) を使用して、HDInsight 上の Spark クラスターを、そのクラスターの標準では搭載されていない外部のコミュニティから提供されている Python パッケージを使用するよう構成することが可能です。
[参照]:スクリプト アクションを使用して HDInsight の Apache Spark クラスターの Jupyter Notebook で外部の Python パッケージをインストールする
- Anaconda がヘッドノード、ワーカーノードにインストールされている為、scikit-learn などの標準的なパッケージはこのインストール手順を利用しなくても、利用可能です
- スクリプト アクションに、/usr/bin/anaconda/bin/pip または、/usr/bin/anaconda/bin/conda のインストーラを利用して、パッケージをインストールするよう記述したスクリプトファイル (BLOB ストレージ上などに配置)を指定してください
Azure ポータルにログインして、Spark を作成した「リソースグループ」、もしくは、「HDInsight」から辿って、自分で作成した Spark クラスター名 (ここでは、seijim-spark) を選択します。「Overview」⇒「スクリプト操作」(スクリプトアクション) をクリックします。
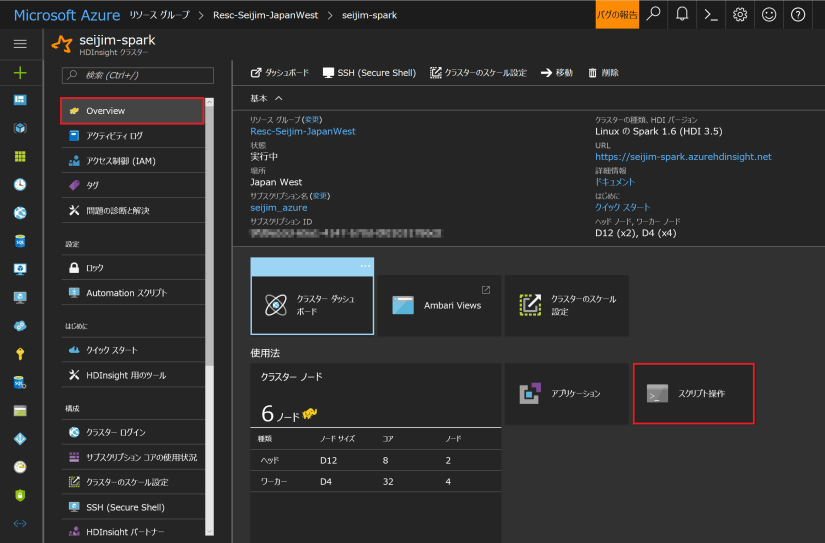
「新規で送信」をクリックし、「名前」「スクリプト URI」(シェル スクリプト ファイルの URI) を入力します。BLOB Storage などにファイルを作成して置いておくと良いと思います。スクリプトの実行先=パッケージのインストール先として、ヘッドとワーカーを指定し、ワーカーノードを増やした時なども自動的にこのインストーラが動作するように、最後のチェックボックスにもチェックを入れておきます。
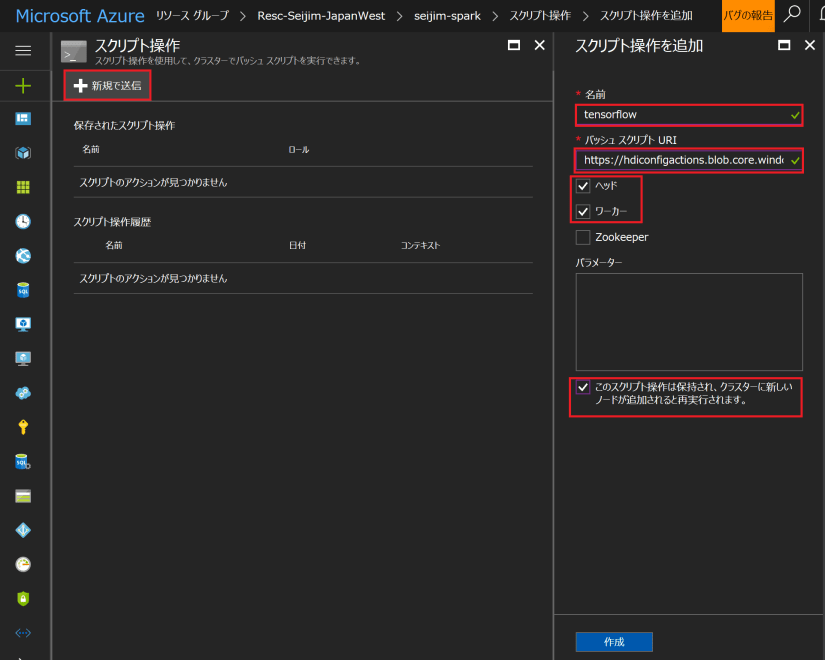
シェル スクリプト ファイルの例は、以下となります。
https://hdiconfigactions.blob.core.windows.net/linuxtensorflow/tensorflowinstall.sh
「作成」をクリックして、5~6分待っていると以下の状態になります。ヘッドノード、ワーカーノードとも、パッケージがインストールされ、利用可能な状態になったことを意味します。
カスタム Python ライブラリの利用方法
Spark が利用している BLOB Storage (Spark クラスター作成時に指定した Storage アカウント名とコンテナー名) に、Azure ポータルや Microsoft Azure Storage Explorer などを利用して、Python ライブラリ (.py ファイル) をアップロードすれば、Jupyter Notebook などから以下のコードを記述することで利用可能になります。
コード例
sc.addPyFile ('wasbs:///userlib/xxxxx.py')
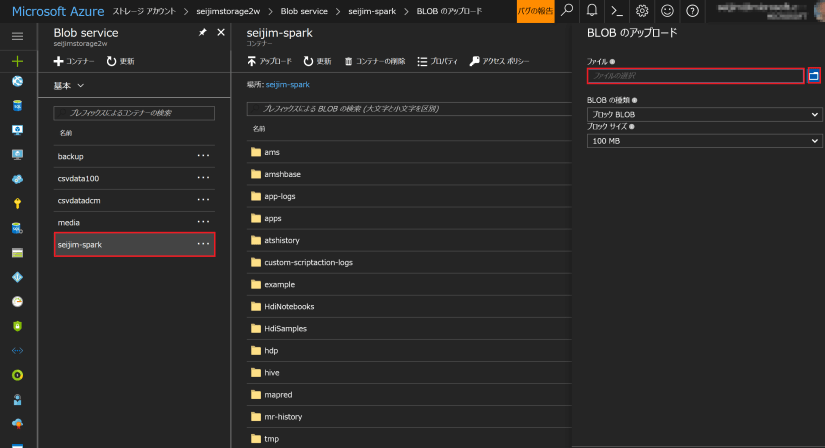
Azure ポータルからファイルをアップロードする際は、対象の Storage アカウント、コンテナーをたどり、「アップロード」を選択してファイル単位でアップロードして頂くことが出来ます。
一方、Microsoft Azure Storage Explorer を使うと、フォルダー単位でアップロードすることが出来、その際、コンテナー配下に論理フォルダーも作ることが出来る為、こちらの方がお勧めです。今回は、「userlib」という論理フォルダーを作っています。


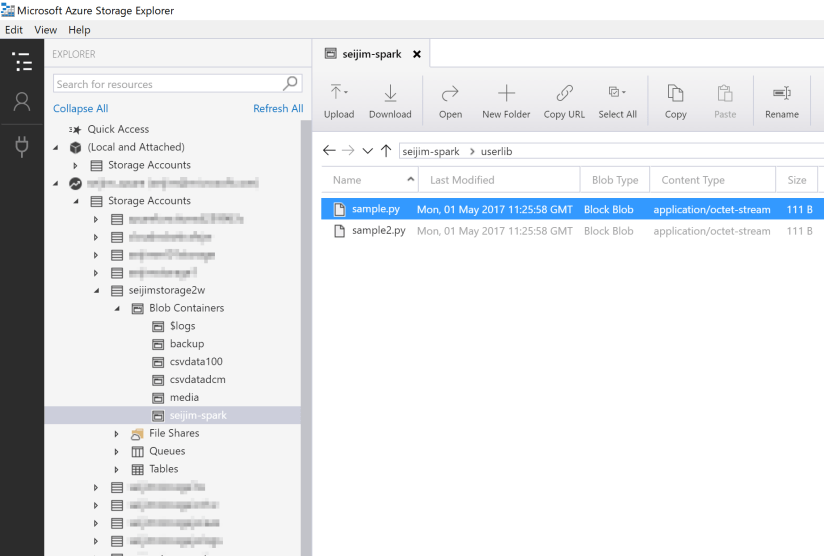
これで、カスタムライブラリが利用可能になります。BLOB Storage が使えるので、とても簡単なのです。
Jupyter Notebook ファイルの移行
Spark on HDInsight における Python コード開発の標準的手法は、Jupyter Notebook です。ということは。。。ローカルで Jupyter Notebook で開発していたら、そのまま持って行けるのでは?
はい、その通りです。PySpark における分散処理にはお作法 (特有の記述方法) があるので、ローカル環境や単一サーバー環境で動作させている Python では、1ノードや 1CPUコアにリソース利用が偏って、遅いという問題はあるものの、先ずは、そのまま資産を利用することも出来るのです。
カスタムライブラリ同様、BLOB Storage の所定の位置にアップロードするだけです!
Spark が利用している BLOB Storage のコンテナー配下にある「HdiNotebooks」論理フォルダーに、Notebook ファイルをアップロードすると、即時利用可能になります。
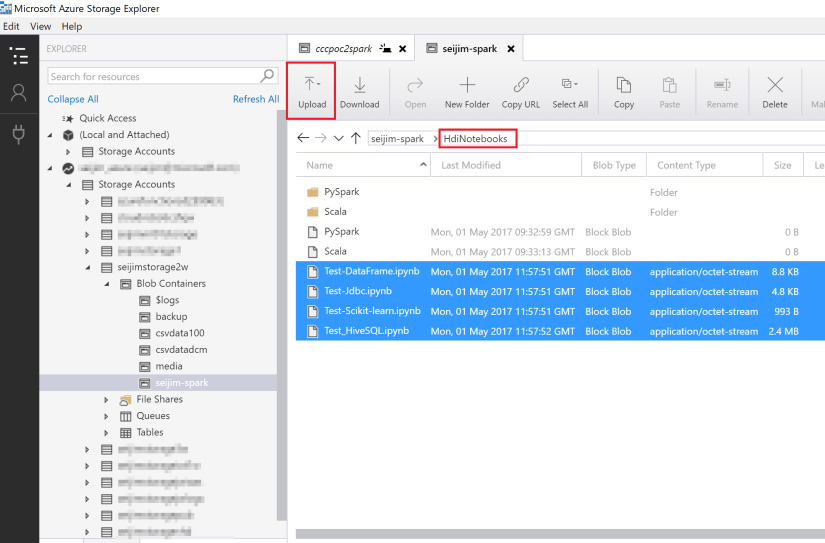
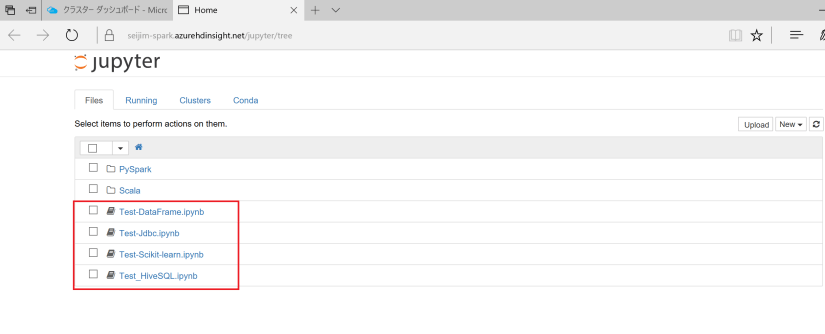
アップロードした Notebook ファイルがそのまま表示されているのが分かります。
Next ⇒ Spark on HDInsight を使ってみる (3) – Python は Jupyter Notebook で始めよう
