HDInsight は、マイクロソフトが提供する Hadoop の PaaS (Platform as a Service) であり、ハードウェア、OS、ミドルレイヤまでマイクロソフトが管理・運用をしてくれますので、Spark クラスターを展開した後は、Python (PySpark) や Scala といった言語に集中することが可能になります。
当初は、Windows ベースしかありませんでしたが、現在は、Linux の方がむしろメインストリームとなっており、特に分析クラスターである Spark を使う場合、Linux 以外の選択肢はないのです。内容的には、Hortonworks の HDP (Hortonworks Data Platform) をベースとしていますので、馴染み易いかと思います。
導入
非常に簡易な手順で、Azure ポータルからディプロイが出来ます。約 10 分程で Spark クラスターを展開できると思います。
先ず、「+」ボタン ⇒「Intelligence+analytics」⇒「HDInsight」を選択します。

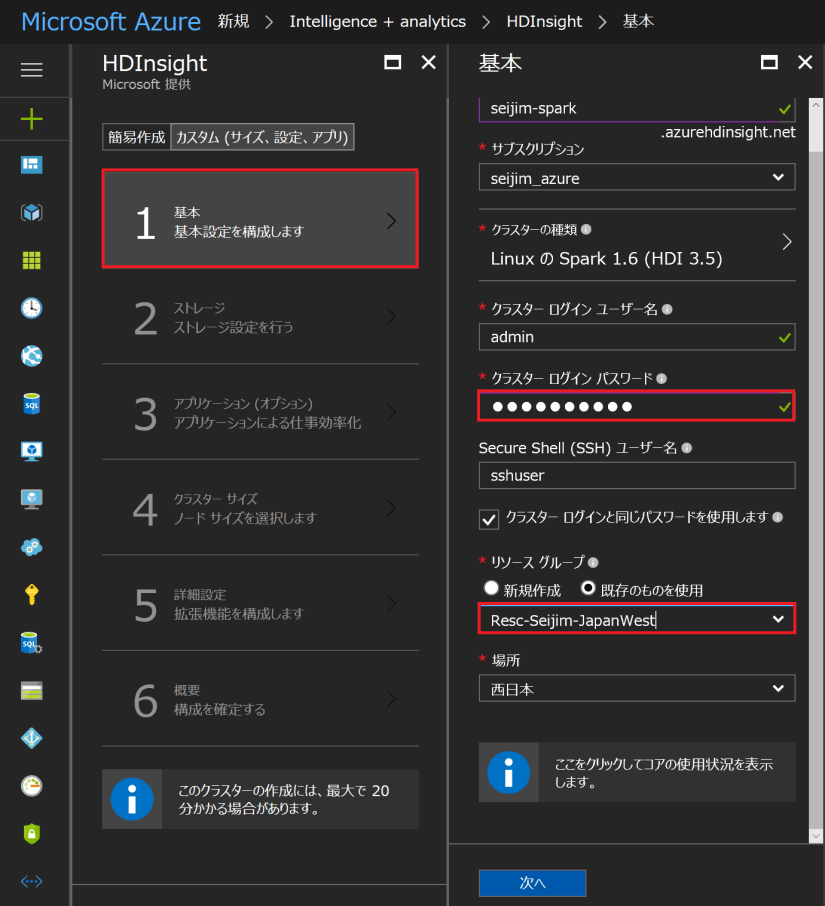
「カスタム」⇒「基本」を選択し、「クラスター名」を入力してください。「クラスターの種類」では Spark を「バージョン」はデフォルトの Spark 1.6.3 (HDInsight 3.5) を選択します。もちろん、より新しいバージョンを選択しても構いませんが、ここで解説する動きと多少異なることがありますので、その点はご理解ください。

Spark (HDInsight) クラスターのログインユーザー名とパスワード、リソースグループを設定します。
次にストレージですが、HDInsight では、HDFS ではなく、通常の Azure BLOB Storage を利用します。Hadoop (HDInsight) から見ると、HDFS API を通してアクセスしますので、HDFS として見えているのですが、私達からは普通の BLOB Storage として扱うことが出来、これはこれで非常に融通が利きます。一方、完全な HDFS ストレージでデータ無制限のスケーラビリティを持つ Data Lake Store も選択可能です。残念ながら、2017/05/01 時点では、日本リージョンには来ておりませんので、ここでは、Azure Storage を選択します。
Storage アカウントは事前に作成しておいても、この段階で作成しても構いません。Storage のコンテナー名も指定しておきます。

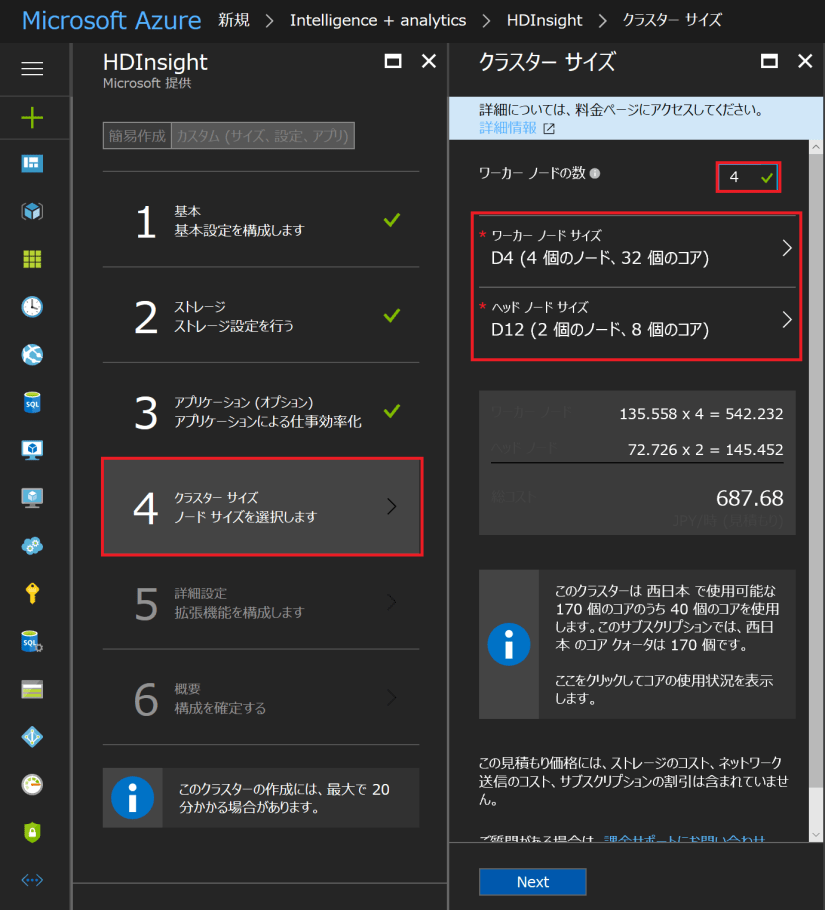
「アプリケーション(オプション)」では特に何も指定せず、「クラスターサイズ」の方を指定します。ヘッドノード × 2、ワーカーノード × N という構成になります。ヘッドノードはジョブ管理、ワーカーノードでデータや処理が並列化されると考えてください。Spark では分散型のインメモリ処理を行いますので、ワーカーノード合計のメモリサイズは特に重要です。ここでは、一先ず、デフォルトのサイズとノード数を利用します。
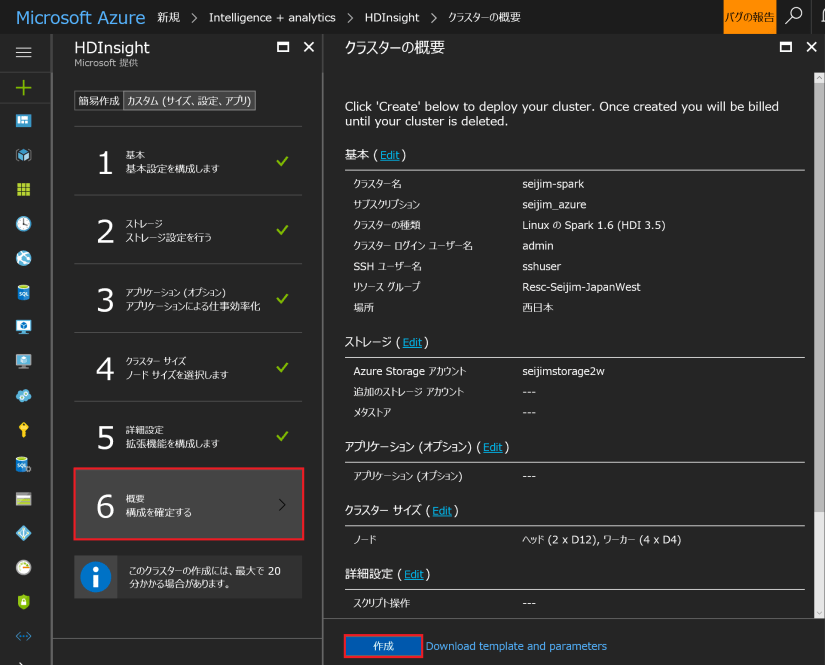
「詳細設定」はここでは飛ばして、「概要」で「作成」を行います。10 分程待って、出来上がりです。Hadoop 上の Spark クラスターがこんなに簡単にディプロイできるなんて!!とても、素晴らしいです。
Next ⇒ Spark on HDInsight を使ってみる (2) – Python を使い始める前に知っておくこと
[参照]
HDInsight:エンタープライズ向けの Spark および Hadoop クラウド サービス
